Построение лексического блока не такая уж и тривиальная задача, как может сначала показаться. Казалось бы, что может быть сложного в том, что бы разрезать программный код на слова, а оказывается сложность есть. Вдогонку ко всему, чистый лексический блок писать не практично, поэтому он уже берет на себя часть обязанностей синтаксического анализатора.
Прежде, чем писать код лексического блока, необходимо определиться с лексемами, для этого приведем пример программы:
X = (0.5E1 + 2 + Y);
SCAN(Y);
IF (Y > (X + 2)) {
PRINT(Y);
}
Y1 = 10;
M0:
IF (Y1 != 20 + 30) {
GOTO M0;
}
Разобьем код на лексемы:
(опер. присваивания, 1) // 1 - номер строки в
// таблице идентификаторов
// пример: X =
(число, 1) // 1 - номер строки
// в таблице констант
// пример: 0.5
(SCAN, 1) // 1 - номер строки в
// таблице идентификаторов
// пример: SCAN(X)
(IF, IF) // пример: IF
((, () // пример: (
(идентификатор, 1) // 1 - номер строки в
// таблице идентификаторов
// пример: x
(), )) // пример: )
(ар. операц, +) // пример: +
(оп. отношения, >=) // пример: >=
({, {) // пример: {
(}, }) // пример: }
(;, ;) // точка с запятой
(метка, 3) // 3 - номер строки в
// таблице идентификаторов
// пример M0:
(GOTO, 3) // 3 - номер строки в
// таблице идентификаторов
// GOTO M0
(PRINT, 2) // 2 - номер строки в
// таблице идентификаторов
// пример: PRINT(Y)
Здесь приведены, только уникальные лексемы для наглядности, так как дважды писать лексему "идентификатор" не нужно.
Теперь вы видите и понимаете, какая задача стоит перед лексическим блоком. Необходимо разбить код на лексемы да и еще в не которых местах проверить синтаксис.
С этой задачей нам позволят разобраться конечные автоматы: детерминированные и не детерминированные, также они решат проблему с производительностью, так как они могут обрабатывать огромные тексты за одни проход. Далее ознакомьтесь с статьями [1], [2], после чего с статьей [3]. Мы будем делать нечто похожее, как описано в третьей статье.
Сначала спроектируем конечный автомат. Я этот делал в файле формата Microsoft Excel. Сам файл можете скачать отсюда, а также всякий случай оставлю "скриншот", для тех кто качать не хочет:
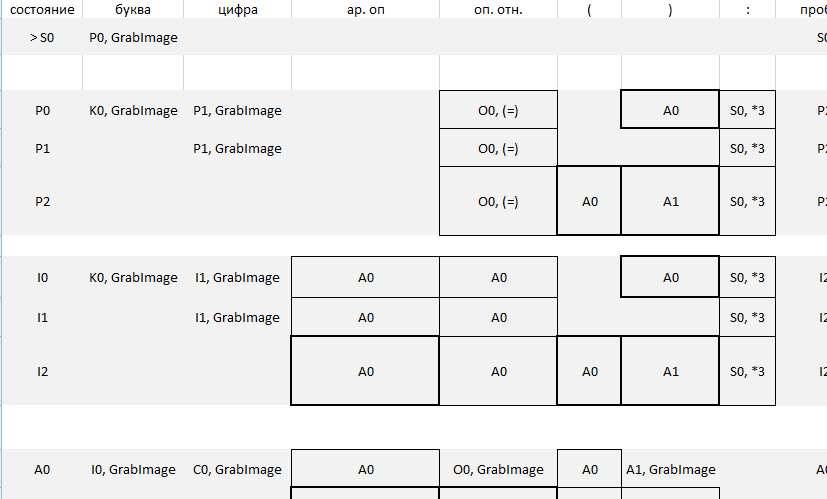
Если вы прочитали, указанные мной, статьи, то для вас не составит труда разобраться с приведенным конечным автоматом. Хотя это может забрать не мало времени. После того, как КА спроектирован осталось перевести его в код на языке программирования C#, аналогично [3] статье.
Код проекта уже с транслитератором и лексическим блоком вы можете скачать отсюда. Проект создан в Visual Studio 2010 Premium.
Если вы заметите ошибки - пишите. Если у вас возникнут вопросы - задавайте их!
Комментариев нет:
Отправить комментарий